
Home
People
Projects
Papers
Courses
Public

|
|
Research Projects
$ Last generated: Wed May 1 13:53:07 2024 EST $
Current Projects
 |
Fact-checking organizations, often known as fact checkers, are instrumental in identifying and debunking mis/disinformation. Despite their vital importances and needs to combat questionable information, however, concerns have been also raised about the potential uncertainty if/when different fact checkers provide conflicting assessments for the same claim. In this FC2 (fact-check fact chekers) project, we aim to (1) build a database and knowledge graph that encompasses the majority of worldwide fact-checked claims/verdicts and (2) study how fact checkers fact-check claims similarly or differently or how fact-checking propagates across regions and languages.
|
 |
The SocialGoodGPT project, partially supported by PSU CSRAI seed grant, researches scenarios, applications, policies, and methods to ensure popular LLMs such as ChatGPT and Gemini to be used to positively and equitably benefit people all over the world. For instance, we develop a framework to use LLMs to detect disinformation generated by humans and other LLMs and examine how LLMs can benefit students' learning in low-resourced regions.
|
 |
The A3 (AI Authorship Analysis) project, partially supported by NSF1 and NSF2, investigates various "authorship"-related issues in the generation, detection, perturbation, and obfuscation of AI-generated human languages such as LLM-generated texts. In particular, we aim to answer questions such as:
what are the characteristics of LLM-generated texts, distinct from human-written texts and how to build efficient and effective Turing Testers to differentiate LLM-generated texts from human-written texts.
|
 |
"Deliberation" is the dialogue between a group that facilitates careful weighing of information, providing adequate speaking opportunities and bridging the differences among participants’ diverse ways of thinking and problem-solving. Collaborating with Univ. of Cambridge and The Univ. of Sheffield, UK, and partially supported by PSU CSRE seed grant, in this DELiBot project, we investigate how
to improve the group’s decision-making by providing a framework for good deliberation practices, by means of an arficial moderator, a DELiBot, across many tasks. In particular, we are investigating how useful a DELiBot can be to help a group of novice and expert users to understand and unearth the differences between human-written and AI-written (deepfake) texts.
|

|
The SysFake
(pronounced as "Cease Fake") project, partially supported by ICS
seed grant,
ORAU,
NSF1, and
NSF2, aims to develop effective computational techniques to detect and prevent fake news, develop educational materials and pedagogy to raise the awareness on fake news, and investigate ways to train humans better not to fall for fake news.
|

|
This
NSF-sponsored SFS program (CyberCorps)
at Penn State recruits and trains a small number of bright
undergraduate and graduate students studying/researching in a broad range of
cybersecurity areas, and aims to place them in federal or state
government cybersecurity positions upon their graduation. College of IST currently
leads the SFS program at Penn State.
|
Past Projects

|
The REU Site: Machine Learning in Cybersecurity program at Penn
State, sponsored by NSF,
is a 10-week-long intensive summer research program for
undergraduate students in US. The theme of Penn State program
lies in the area between Machine Learning and Cybersecurity. The
topics of research include fake news mitigation, cognitive minds
to predict frauds, smart contract frauds, crowdsourcing and
misbehavior, adversarial production-run failure diagnosis,
astroturfing, privacy in conversation agents, etc.
The program is part of many NSF
CISE REU Site
programs nationwide.
|

|
This interdisciplinary Memory Illusion project (logo borrowed from here),
partially supported by
SSRI seed grant and
NSF,
aims to provide reliable information and improve people’s trust in what they read online using the techniques from machine learning and the theory from psychology. The project will advance state-of-the-art machine learning methods to model the psychological phenomenon known as memory illusion, which are memory errors that individuals make when remembering, interpreting and making inferences from past experiences and knowledge.
|
 |
The Precision Learning (PL) project, supported by
NSF,
is the collaboration among Penn
State, U. Arkansas, and WPI to study
causal relationships among diverse factors between students
(e.g., skills, interests, demographics) and learning medium (e.g.,
topic/length of videos, demographics of speakers) and develop:
(1) a deep learning based video analysis algorithm to extract fine-grained metadata from videos,
and (2) a fairness-aware personalized recommendation algorithm to matchmake
students with right educational videos (as in the "Precision
Medicine") with little discrimination and bias.
|
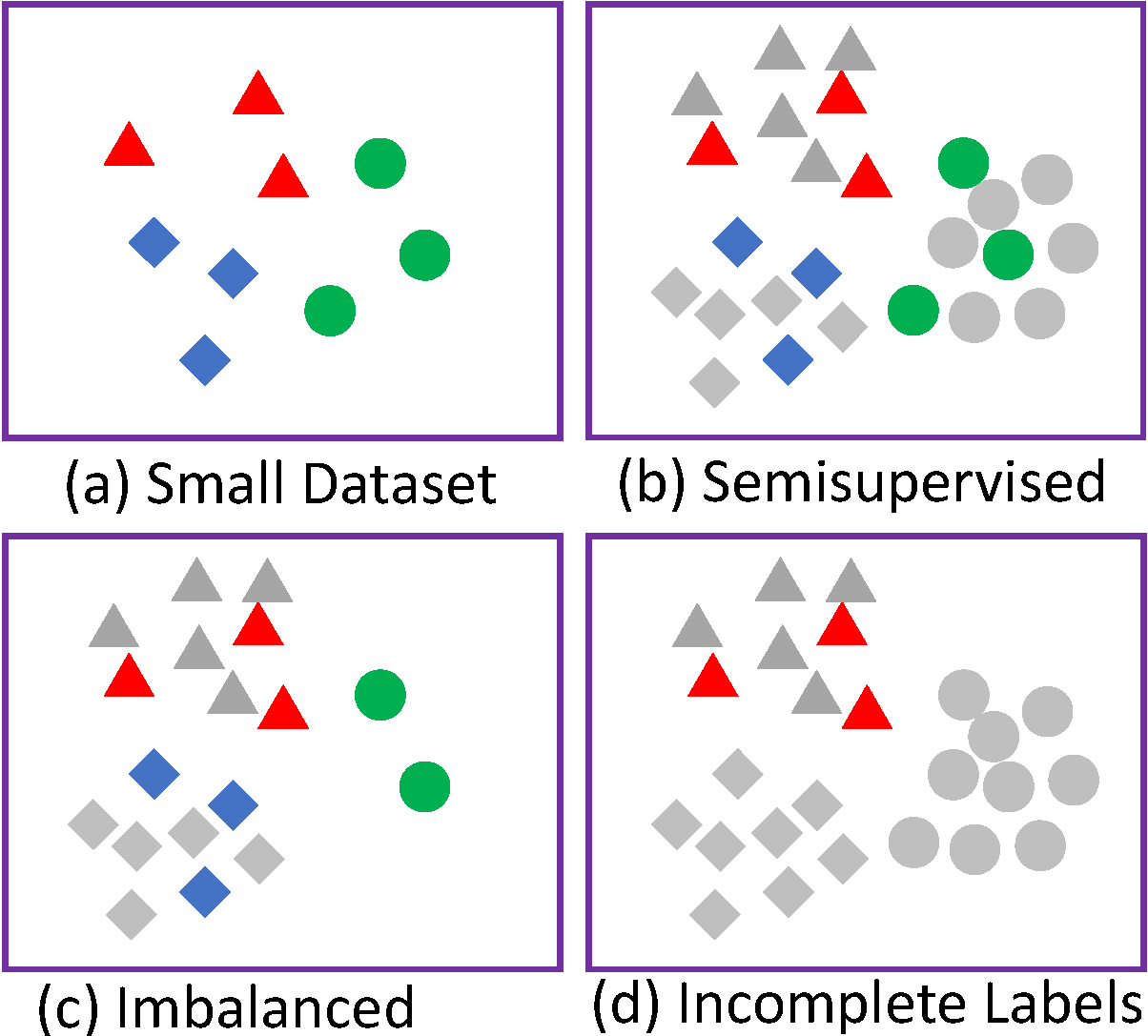 |
The Label Generation (LabGen) project, supported by
NSF,
attempts to address the settings where many real-world machine
learning and deep learning applications
come with only data with limited label information
(i.e., a small amount of labeled data or no labeled data), and proposes
three novel solutions: (1) labeled data generation with
limited labeled data, (2) labeled data generation with weak
supervision, and (3) labeled data generation with limited human involvement.
|

|
The Likes-R-Us
project, partially supported by IST seed grant and Samsung, aims to study various
properties and latent relationships found among "Like" activities and
the "Like" networks formed thereof. We study the questions involving
the structures, influences, and contexts found in Like networks, and
their influences and impacts toward users in social media.
|

|
The Nittany GenCyber program at Penn
State, sponsored by National Security Agency (NSA) and NSF, is a
full 5-day summer camp geared toward high school Science, Math
and Technology teachers to provide the fundamentals of
cybersecurity’s first principles and their connections to data
science. In 2018, the program runs from July 30 to August 3,
2018 in the College of IST. The program is part of many GenCyber
programs nationwide.
|

|
The HUman-in-the-Loop Computation (HULC)
project investigates novel problems and solutions to use both machines and human in harmony
for computationally challenging tasks arising in Databases, Information Retrieval, Recommender Systems, and WWW domains. For instance, we develop novel algorithms to efficiently compute Top-k queries via crowdsourcing, or collaborative filtering techniques with the sparsity and cold start problem addressed by crowdsourcing.
|

|
The Social
Circle project, partially supported by NSF and Microsoft, develops methods to: (1) detect the discrepancies
between users' information sharing expectations and actual information
disclosure; (2) design a user-centered yet computationally-efficient
formal model of user privacy in social networks; and (3) develop a
mechanism to effectively enforce privacy policies in the proposed
model. In particular, this project develops a concept of Social
Circles to model social network access within a Restricted Access and
Limited Control framework.
|

|
The Samsung-sponsored SUM (Social User Mining) project aims to develop novel algorithmic solutions, working prototypes, and innovative applications for mining diverse demographic and profile information of users (e.g., gender, age, marital/parental status, home location, job, political opinions, religion) in social network sites such as Facebook, Twitter, and Foursquare.
|

|
In the MOP
(Mobile-Optimized Page) project, we investigate techniques to improve
the mobile-friendliness of web pages (i.e., whether pages are rendered well in mobile web browsers) in diverse contexts and
applications.
|

|
The concept of Web Services has been recently proposed as
a means to achieve the true Intelligent Semantic Web paradigm,
but it still lacks of many necessary functionalities. In the Atherton
project, in particular, we are interested in developing a new Web
Services modeling methodology, Web Services generation and
composition framework, and Web Services based applications.
|

|
The LeeDeo (LEarning
and Educational viDEO search engine and digital library framework)
project
attempts to build web-scale academic video digital libraries using
the search engine paradigm. In particular, we are developing
techniques to automatically crawl and identify so-called academic
videos, and to extract relevant video metadata therein.
|

|
The NSF-sponsored I-SEE project
develops three creative learning modules in Second Life on
topics in computer security: (1) a learning module to
improve students' understanding of what can be done to help
businesses protect themselves against obvious security
threats; (2) a learning module to develop a deep
understanding of the inner workings of complex security
software and hardware; and (3) a learning module that
promotes awareness and education of security issues using
Second Life as a digital storytelling platform.
|

|
In the Data Linkage
project, we re-visit the traditional record linkage problem to cope
with novel challenges such as intricate interplay of match vs. merge
steps, increased scalability, and agile adaptivility. In particular,
as solutions to the challenges, we study four sub-problems: the
googled linkage, parallel linkage, group linkage, and adaptive linkage
problems.
|

|
Is a journal A in a field X
better than a journal B in a field Y? Which venues are
the best place to submit your papers? Currently, there is no
universally agreed method to answer these interesting questions. In
the AppleRank project, toward these
questions, we aim at developing a novel framework that can rank
bibliographic entities (termed as "apples") better.
|

|
In order to meet needs for flexible and
efficient support of access control systems for the XML
model, the L3 project explores
how to leverage on techniques developed for relational
access control systems.
|

|
In the QUAGGA project,
we investigate research issues in the "Quality of Data" (QoD) to
achieve clean databases. The existence of poor or erroneous data in
databases causes the so-called Garbage-in, Garbage-out problem.
As the sources of data become diverse, their formats become
heterogeneous, and the volume of data grows rapidly, maintaining and
improving the quality of such data gets harder. Therefore, in this
project, we study database-centric data quality and cleaning problems.
|
|
The OpenDBLP project renovates the old DBLP system into
a Web Services based on-line digital library, where not only human users but also software agents can issue queries to retrieve bibliographic information.
As a killer application, the DBLP system itself was completely simulated with the Google flavour, too.
|
|

|
| |